Of Math and Memory, Part 2
by radimentary
Last time, I wrote that having a good memory is essential in mathematics.
Today I will describe my model for working memory.
Compression and Prediction
Data compression is the science of storing information in as few bits as possible. I claim that optimizing your working memory is mainly a problem of data compression: there’s a bounded amount of data you can store over a short period of time, and the problem is to compress the information you need so that this storage is as efficient as possible.
One of the fundamental notions in data compression is that compression is equivalent to prediction. Another way of saying this is: the more you can predict, the less you have to remember.
Here are three examples.
I. Text compression
Cnsdr ths prgrph. ‘v rmvd ll th vwls nd t rmns bsclly rdbl, bcs wth jst th cnsnnts n cn prdct wht th mssng vwls wr. Th vwls wr rdndnt nd cld b cmprssd wy.
All text compression algorithms work basically the same way: they store a smaller amount of data from which the rest of the information can be predicted. The better you are at predicting the future, the less arbitrary data you have to carry around.
II. Memory for Go
Every strong amateur Go player can, after a slow-paced game, reproduce the entire game from memory. An average game consists of between one and two hundred moves, each of which can be placed on any of the 19×19 grid points.

A typical amateur game, midway through.
Anyone who practices playing Go for a year or two will gain this amazing ability. It is not because their general memory improved either: if you showed them a sequence of nonsensical, randomly generated Go moves, they would have almost as hard of a time remembering them as an absolute novice.
The reason it’s so easy to remember your own games is because your own moves are so predictable. Given a game state, you don’t have to actually remember the coordinates where the stone landed. You just have to think “what would I do in this position?” and reproduce the train of thought.
The only moves in the game you really need to explicitly store in memory are the “surprising” moves that you didn’t expect. Surprise, of course, is just another word for entropy. The better you are at prediction, the less surprise (entropy) you’ll meet, and the less you have to remember.
III. Mathematical theorems
A general feature of learning things well is that you get better at predicting. Fill in the blank:
If 
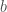
A beginning student looks at this statement and recalls the answer is 
A practiced number theorist doesn’t need to store this exact statement directly in memory; instead, they know that any of an infinite variety of such statements can be reconstructed from a small number of core insights. Here, the two core insights are that a sum of two squares is the norm of a Gaussian integer, and that norms are multiplicative.
Getting better at prediction in mathematics often follows the same general pattern: identifying the small number of core truths from which everything else follows.
We reduced the problem of improving your working memory to the problem of predicting the future. At face value, this reduction seems less than useless, because predicting the future is harder than memorizing flash cards. Thankfully, human beings are embodied agents who can interact with our world. In particular, we can cheat by instead making the world easier to predict.
More on this next time.

Part 3 coming any time soon 🙂 ?
Probably by the end of May. 🙂
Can’t wait!
[…] In Part 2, we gave a simple conceptual model for short-term memory, based on a fundamental principle of information theory: compression is equivalent to prediction. The more predictable data is (or the better we get at predicting it), the less new information you have to store. […]
[…] of this section was already covered in Of Math and Memory (part I, part II, part III), but I’ll reiterate here the relevant bits. Mathematical proofs are rarely meant to be […]